
We’re a week past the annual (and much-anticipated) “PECOTA Day.”
Have you ever taken a casual stroll through the depths of any public projection systems, and come away with the impression you must be missing something?
The popular attitude toward projection systems these days seems to be some combination of the following sentiments:
a) what exists is more or less as good as can be done with the available tools,
b) all projections are imperfect,
c) we should generally trust the projections (because how can we be confident that our own perhaps less systematic analysis is more valid than the output of a system already optimized for accuracy?).
The tension in those statements should be evident. On the one hand, projection systems are acknowledged as necessarily flawed and oversimplified; on the other hand, we value their ability to synthesize data in a more consistent way than we would otherwise be able to. What, then, are we to do when putting an overall value on a player? To what extent do we trust the projections?
Browse through the outputs of PECOTA or Steamer or ZiPS, and it’s clear that the projections quite often take us to fairly uncomfortable places. For instance, here’s how PECOTA ranks the following batters in expected offensive output (total offensive runs above average per PA, i.e. (RAA+BRR)/PA from the PECOTA weighted means forecast, expressed in wRC+ form):
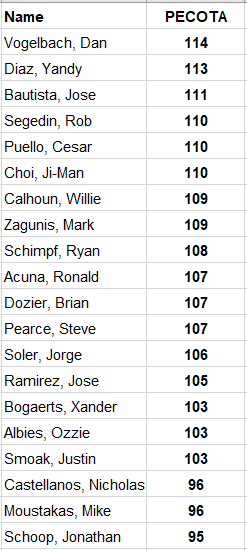
In which of these camps do you wind up? When you’ve encountered instances like this, what tends to be your reaction? What among the following options seem true to you? A) I still have decent faith in such a system, because in the aggregate it appears accurate. B) It’s likely PECOTA knows something we don’t (yet) about Jose Ramirez and the others. C) No, it shows the system is fundamentally broken and can’t be relied upon.
[B] seems hard to swallow, in light of the sheer reality of how projection systems function. A projection system is a program, a system of logic which follows the rules you feed into it. It doesn’t “know” anything you didn’t tell it. So, the issue in response to an output as the above is still reducible to… “is the logic running this program correct?” … as opposed to ascribing a heightened dimension of synthetic intelligence to an anthropomorphized circuit-board scout.
The system en masse is not going through any sort of recursive process, where it “learns” on its own… it only “knows” what it’s told. (And truly, even if some aspects of such a system utilized iterative “learning,” such as a similarity-based aging function, it would still only “learn” according to the instructions and frameworks provided by its creators. More concretely: any machine learning in projection tends to reduce to re-running some very simple functions (of human choosing) a high number of times, seeking a goal which human instruction instructed it to seek, and a definition or metric of value chosen by human instruction, likely relying upon classifiers chosen by human dictation.
So [B] is not something which seems to pass muster. Projection systems work according to the principles they are taught. The outputs on their own are then representative of the quality of those principles/logic. Nothing special or mystical happens. It takes on no intelligence higher than that it’s fed. It outputs the instructions of its logic, its dictates. It’s that simple. So we’re free to just deal with the apparent validity of said logic.
So, we’re left between [A] (keeping the faith, because it’s accurate in total, and in fact trained to be so) and [C] (it’s broken and therefore can’t be expected to provide useful insight about player value in a given instance).
Let’s not even deal with claims of relative “accuracy” for now, as the notion of accuracy itself is plenty problematic. Let’s just look at the mentioned players and solicit some other opinions. How might the ZiPS system see these same players? You’ll probably begin to pick up on the point of this exercise:
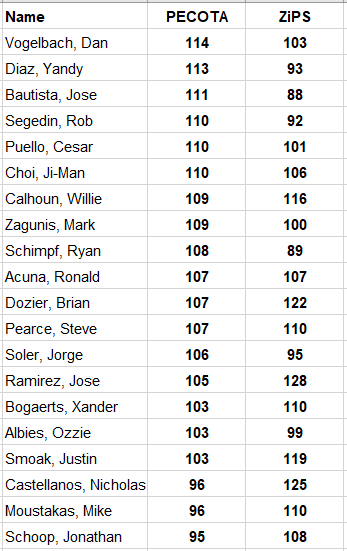
The point of this is not at all to pick on PECOTA. Which one of the answers is “true” or “accurate” in any given case? What do you think? Who is right about Yandy Diaz, Justin Smoak, Willie Calhoun, Nick Castellanos?
Hold those answers for now. Just to further highlight the point, and add the third of the dominant systems… here’s a selection of starting pitchers ranked best to worst by Steamer via ERA-. For pitchers who aren’t projected as 100% SP by each system, we’re normalizing their projection according to Tango’s “rule of 17” (i.e. pitchers see a 17% reduction in RA when moving to the bullpen):
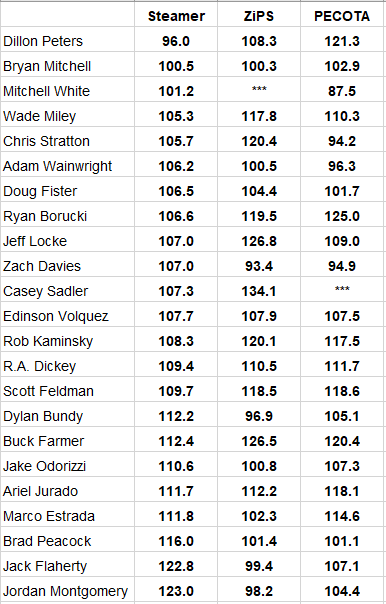
Do you see the point that’s being made? And do you recognize this feeling, from your experience browsing through such outputs?
Scroll from left to right on each hitter, each pitcher. Who is “right”?
All one must accept is that these estimates are not capable of being simultaneously accurate, or equivalently so, at the same time. While perhaps we can’t affirmatively establish which is “right,” all we need to acknowledge is that they aren’t each simultaneously “right” nor equally so. Schrodinger’s “bat” (or ball) is not in play here. The player’s talent level is what it is, one single value; not multiple values, simultaneously, in suspended state. At the present time, Jose Ramirez is either a better offensive player than Willie Calhoun or a worse offensive player than Willie Calhoun, but he is not both. That’s all we’re concerned with here.
So then what? Each system has claims to accuracy, and generally speaking, they run out as more or less equivalent when subjected to common forms of testing. Yet, again, they can’t each be “right” on a given player, and often their answers are wildly different.
You’re in charge of a team. You have to make decisions. What would you do? How would you navigate the discrepancies?
A common, intuitive response; the answer is somewhere in between. There’s a way to combine these competing takes, so as to maximize our individual accuracy.
Well, that would be a dangerous road to take.
For one, regression, in many forms, is something that’s already being handled within these systems themselves. For two, a hot topic in the world of forecasting in the recent past, due to certain domestic events, is “correlated error”, a concept which is certainly be in play here. If these systems are “wrong” about a player’s talent level, sometimes or often they will be wrong for the same reasons, rather than competing reasons (let alone equivalently competing reasons). But third, and most important of all… is it actually helpful to add in the opinion that Mike Moustakas and Nick Castellanos are worse than the MLB-average on offense? Is that a useful take to incorporate into your picture? If it is, why not add the opinion that Hernan Perez is a better hitter than Miguel Sano? After all, it’s *possible* that winds up being true, both this year, and in fact for the rest of their careers. But what isn’t possible, and what’s at root here, is to support this claim via any intelligible reading of their record as ballplayers. And therefore, it simply doesn’t belong as evidence.
Finally, combining several outputs makes it much more likely that one simply compresses the nature of reality, and while doing so may reduce the odds you’re out on some crazy limb with respect to a certain player, this would be achieved at the expense of the ability of a team to have an evaluative advantage. If competing takes on Cesar Puello are that his offensive talent amounts to a 110, 107, 97, 89, 92…. Averaging together will likely reduce aggregate error on the next 500 “Cesar Puellos” who are evaluated. But given we know that he can’t be all these things at once, and is indeed probably either a 104 or 93 but not both, the compression approach will severely constrict our ability to successfully identify underrated talent (or convert overrated talent), even if it reduces our odds of appearing silly in any given case.
In these pages, we’re not going to solve the question of who is the most accurate. And we’re also agnostic on the popular concepts of accuracy.
Though what’s difficult to justify, in light of the above, is where much of modern sabermetrics has been spending their attention. More on this in a moment.
Why This Matters
Here’s what we hope to have established above.
1) If one system says 4.60 and the other says 4.15 and another says 3.95, they’re not each “right” at the same time. And it’s hopeful at best, facile at worst, to presume the “truth” is produced from systematically combining the different opinions.
Here’s what we haven’t established, but should be fairly self-evident:
2) The difference in establishing the truth of this answer matters, and matters *tremendously*.
A difference of even 5 points of wRC+, over 600 PA, is around 3.6 runs, or ~$3.2 million in value. And that’s just for one player, in one season. Multiplied out over several years, for the full range of players that a team needs to be able to assess… it’s very easy to see how even slightly more accurate evaluations can yield massive benefits, and slight inaccuracies (leaving aside the clearly absurd examples) can lead to great peril. Much more important than whether a given player should be expected to produce a 103 or 108 in the next season is the asset value of a Calhoun, Acuna, Choi, Davies, or Peacock. These values hinge on the long-term forecast, which expands or contracts wildly if today’s starting point is 4% higher, or 9% lower.
This is the root at which all teams compete with one another: the evaluative. From the 8th roster spot to the 38th. From the $1.1m commitment to the $110m commitment. These evaluations and resulting decisions comprise the lion’s share of what differentiates successful organizations from unsuccessful ones (randomness notwithstanding).
Here’s more we haven’t yet established, and is perhaps less self-evident, but we’ll hope to convince you:
3) ZiPS/PECOTA/Steamer are not at all wildly different from the range of quality of the evaluative systems you’ll find being used within teams.
Really?
Well, consider a few things. ZiPS is a ~20 year project led by one of the most prolific sabermetricians in known history in Dan Szymborski, a godfather of baseball projection, who surely draws upon the wisdom of the research community and informed friends/colleagues over these decades. Steamer is a ~10 year project primarily driven by Jared Cross, who teaches math and science at an elite New York school, and colleagues/collaborators who themselves have impressive accomplishments. PECOTA was created by the legendary Nate Silver, and has since been in the custody of several hands, including Colin Wyers, who now plays a leading role in analytics for the vaunted Astros, and Harry Pavlidis and Jonathan Judge, who are among the leading lights on the modern sabermetric horizon. Focusing on these three systems makes no mention of others, such as Mitchel Lichtman and Clay Davenport, whose professional efforts in player projection each span decades. And there are others.
They know what they’re doing. They’ve all spent countless hours optimizing their systems. And yet, with remarkable frequency, they’re still coming to substantially different answers to one another. And they’re not each equally correct in each instance. Certainly NEIFI is not, either—so big of us to admit!
This stuff is difficult, bottom line. Hiring a handful of advanced degrees and letting them go to work for a couple or a few years is no guarantee of even matching the quality of one of these systems, let alone achieving a meaningful improvement. That’s certainly not to say a dramatic improvement isn’t possible, and we firmly believe it is. It’s only pointing out that this achievement isn’t something that can be rationally expected merely on the basis of the resumes (or other characteristics) of those doing the work.
This is difficult. This is not a settled science. There is a vast range of differences, and outputs, and they cannot all be equally correct. And Ballclub X may or may not be doing a job that’s much different in overall quality to the PECOTA team or Steamer or Clay Davenport.
What we haven’t yet established, but is the larger point of this piece:
4) You’re (probably) not ready for Level Two (or beyond).
All of the player-to-player contested space you see exemplified above (which is absolutely huge) is concerned with the interpretation of the performance record. That’s it. These are the differences that arise solely from interpreting historical performance records, in order to tell how good people are at baseball.
How do we measure pitching effectiveness? How do we account for park factors, quality of competition? How should the performance from three years ago weigh versus the performance from the most recent year? How do we separate pitching from defense, or from catching? How do we separate offensive output from randomness, or quality of competition? How should different types of players be expected to age? Etc etc etc.
That’s all that’s driving these differences. We’re reaching vastly different answers. They’re not each correct. Sometimes, that’s blindingly obvious. Most of the time, less so. Virtually always, those differences add up to millions of dollars of value.
The second pernicious assumption, in addition to the belief that teams are likely far further advanced than the public systems in this pursuit, is that the gap between a ZiPS and a Steamer and a PECOTA is due to teams having much more information (data) than these systems have.
Think about that for a moment. Think about the differences you see above. Think about how they’re interpreting very similar information and data sets, and see the range of their answers player-to-player, even among long-established regulars.
Does it make sense that these differences would be “solved” via additional granularity, and more data? As in, if you gave ZiPS and PECOTA the Statcast dataset, they’d begin to more or less agree on players? Does that make any sense?
For one, many of these systems actually are incorporating at least a chunk of such data already. But pretend they weren’t.
If anything, additional layers of information would probably extend the differences amongst the systems, because they expand the available space for differences in theory/approach in interpretation of the record.
Regardless of the type of data being used, whether it’s results-based or something more granular, some sort of projection system architecture is necessary in order to properly make sense of it. Statcast data is merely another type of performance data, as opposed to somehow being a standalone projection tool in and of itself.
But what we’re led to believe many teams are concerned with these days are questions that fall into the realm of player development rather than true-talent assessment. Questions such as…. if we alter this pitcher’s release point, we should expect to optimize his slider movement, which would therefore make him better by Y. If this hitter can be taught to alter his launch angle, particularly given his swing path, his expected production would move from N to Q, therefore his asset value is actually much higher. If this reliever would optimize his sequencing, he’d go from a pedestrian 3.60 to an elite 3.05.
Wait, wait, wait.
Very smart, talented, experienced people still can’t agree on how relatively good Jose Ramirez, Jorge Soler, Willie Calhoun, and Daniel Murphy are at offense generally. Not even close, really. Or on how good Zach Davies is relative to Chris Stratton relative to Brad Peacock relative to Anthony Banda relative to Marco Estrada at run prevention. (And, years before today, Ramirez or Murphy or Peacock or Calhoun among their contemporary prospects.) And without clarity on these questions, teams are flying blind as to the expected value changes brought about by their player development efforts.
Given that, one has little reason to be fishing in the pond of using performance data to alter players for value-based reasons. Not until they’re ultra-secure in their view of player talent to begin with. And judging by the landscape of public projection, which is at worst a decent proxy for projection going on within teams, it’s clear that most teams just aren’t there. Which means efforts built on top of such structure are much more likely to merely yield additional noise, rather than additional precision and insight.
Suppose you’re running a team and you indeed have built your own in-house projection system, comparable in quality to the most popular publicly available systems. What do you do with that? Do you use your own system exclusively, just because it’s your own system? If you do that, you’ve merely arrived at something different, not better, and presumably spent a fair amount of time and effort to get there. Do you average your system’s output with that of the other systems? Leaving aside the fundamental problems with that approach (as outlined earlier), if you do that, you’re getting very limited utility out of your system, since it’s functioning as merely a fraction of your overall assessment.
The point being: merely creating another ZiPS or Steamer serves no real purpose unto itself. To be of value to a team, a system needs to be substantially better. It needs to provide actionable information, which means it needs to possess qualities that allow the team using it to confidently trust its outputs and, by implication, dismiss the outputs of other systems when they conflict with those of the team’s own system.
Until one has achieved exactly that, and has great confidence that they have, there is questionable reward, and perhaps great danger, in committing focus to the developmental layer without a clean evaluative layer.